1 Batch
1.1 Review: Optimization with Batch
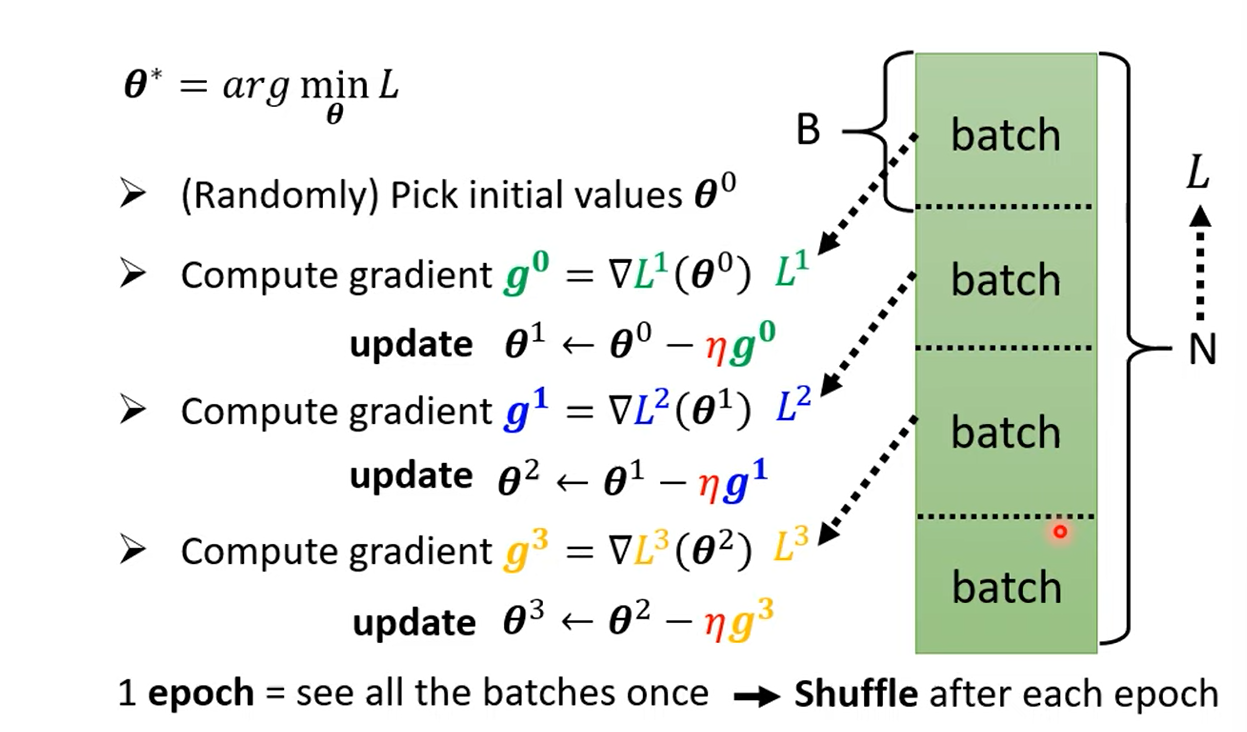
1.2 Small Batch v.s. Large Batch

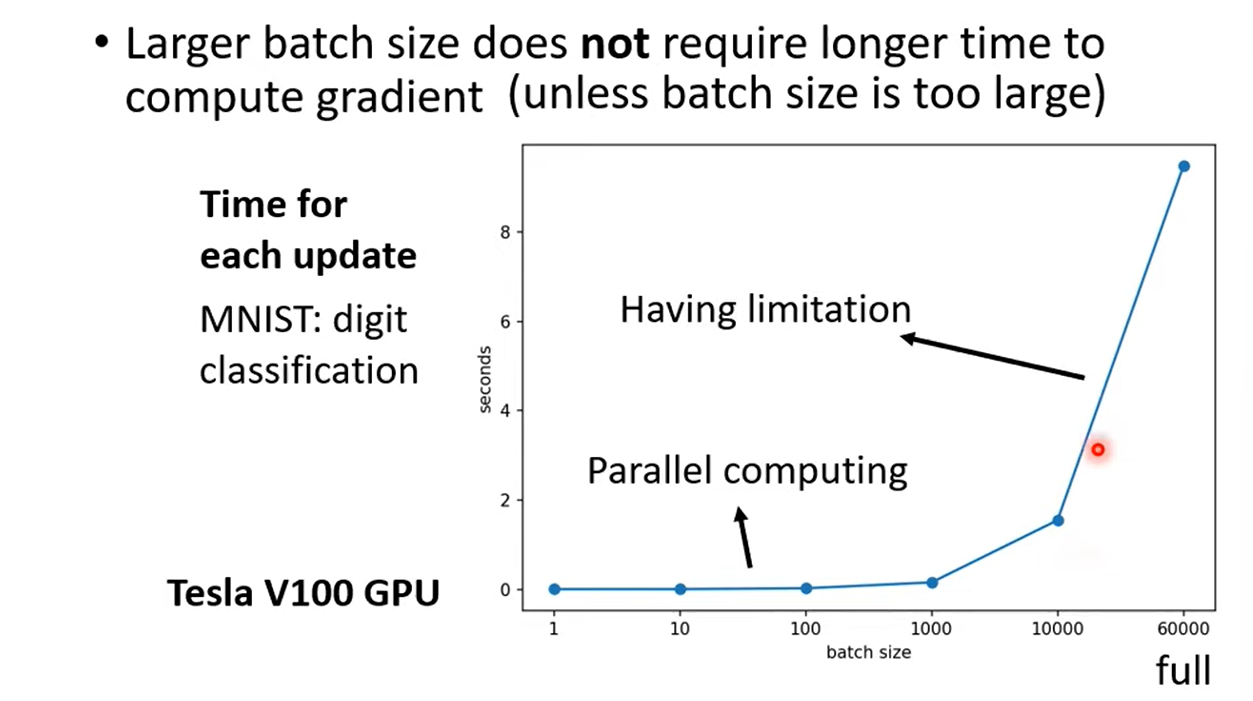
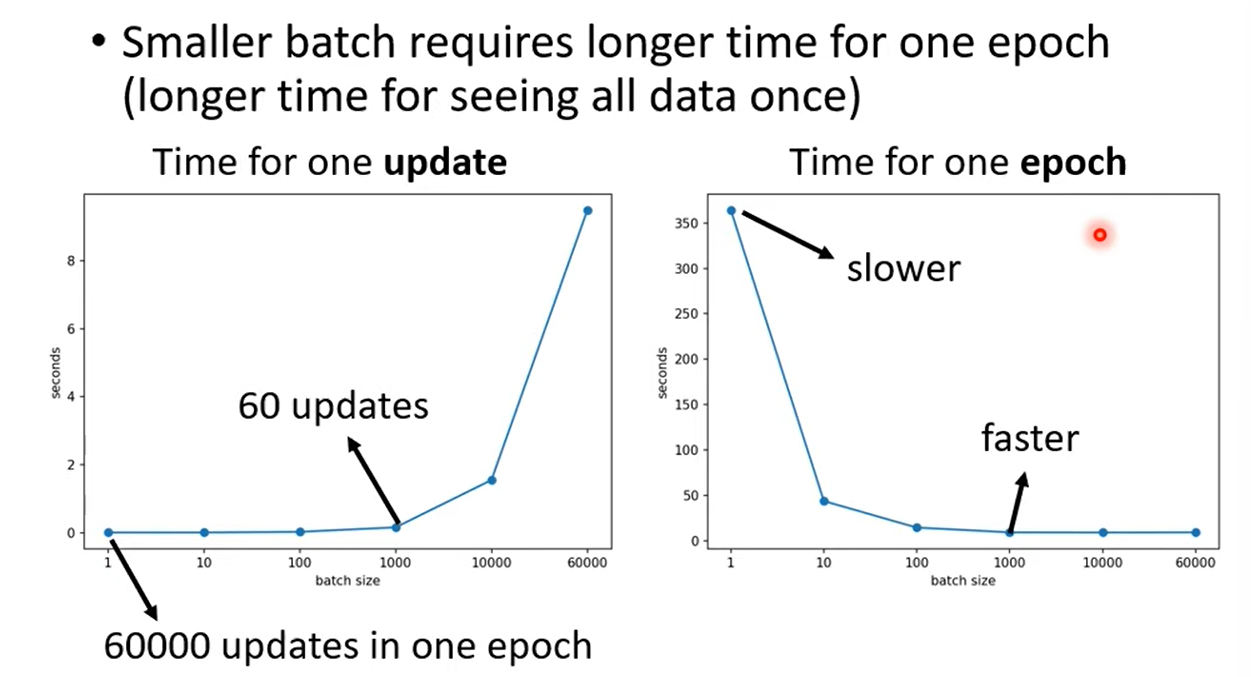
1.2.1 Training Time
Parallel Computing
1.2.2 Performance
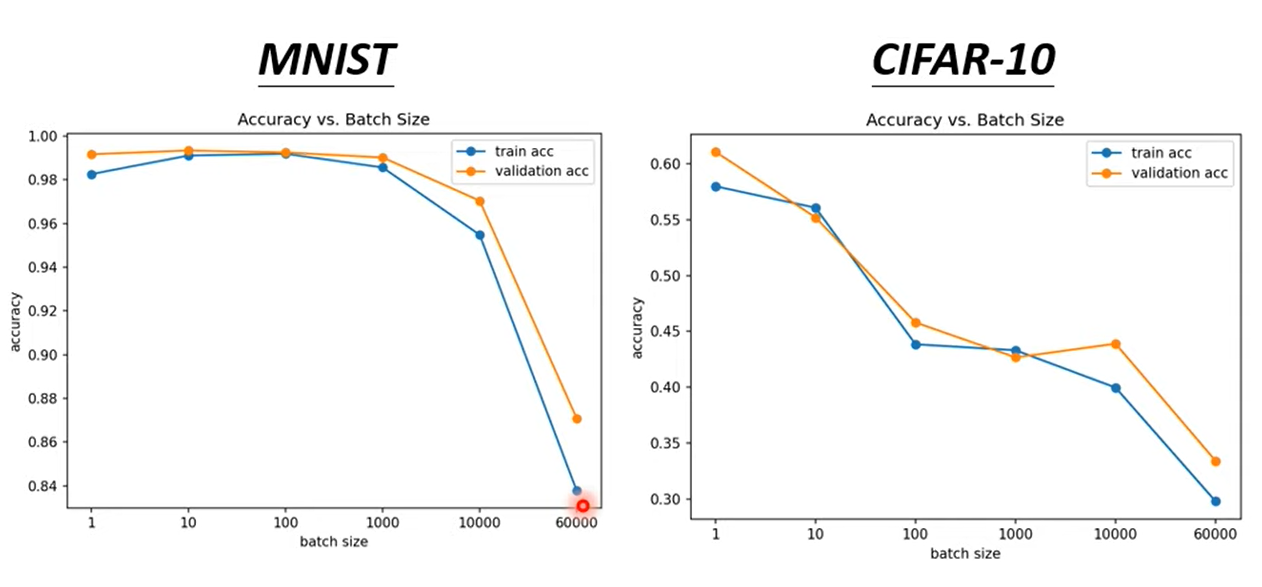
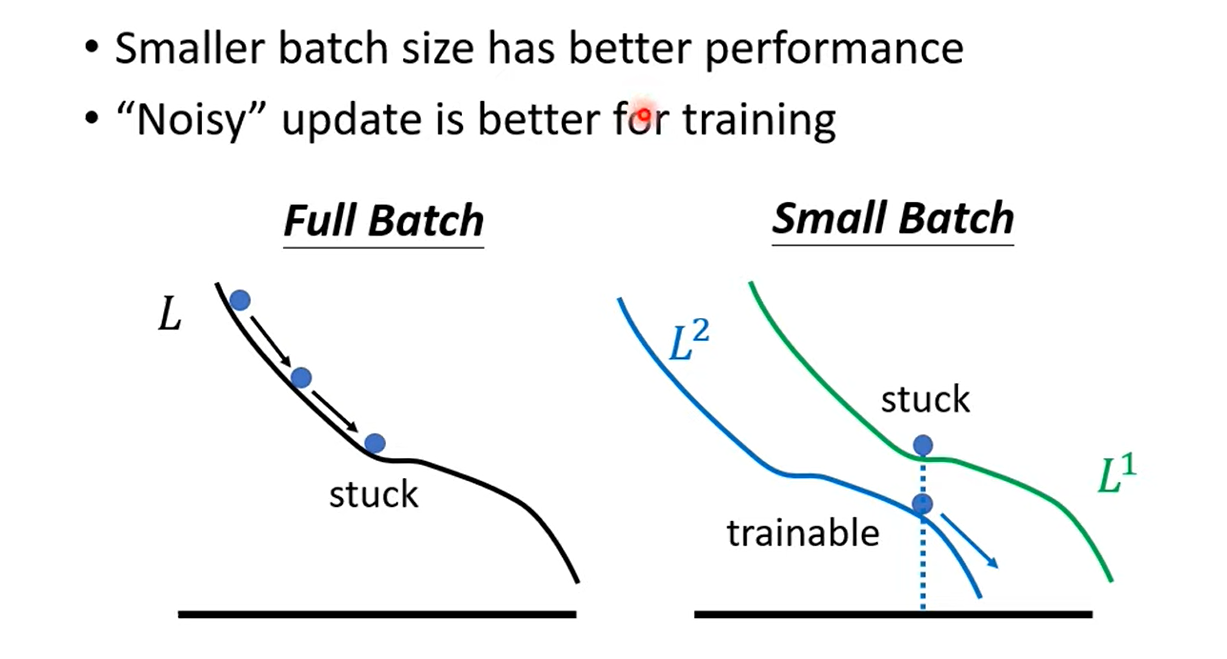
- Small Batch size has better performance for training data.
- What’s wrong with large batch size on training data? Optimization Fails.
- Smaller batch size and momentum help escape critical points.
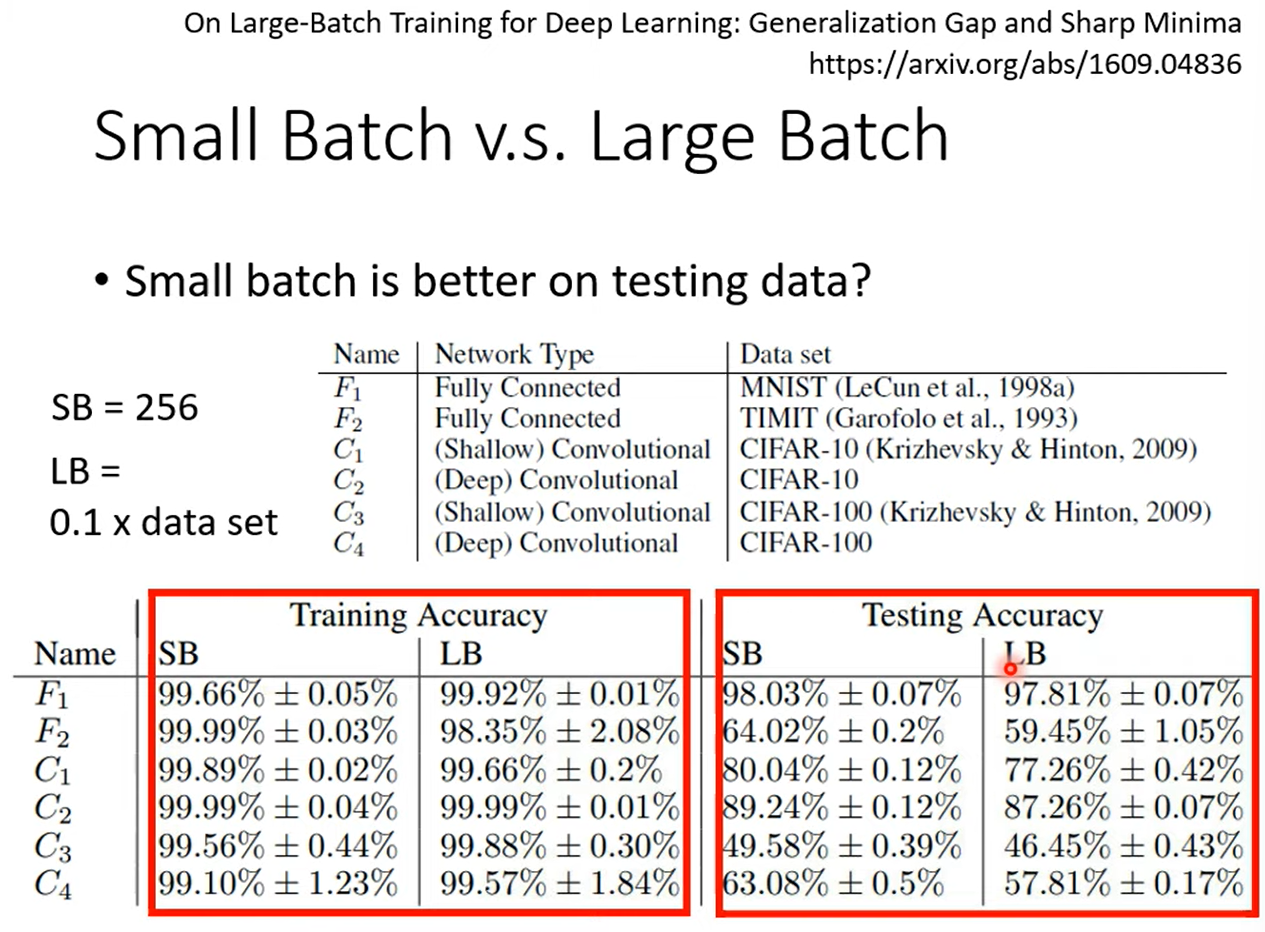
- Small Batch size has better performance on testing data.
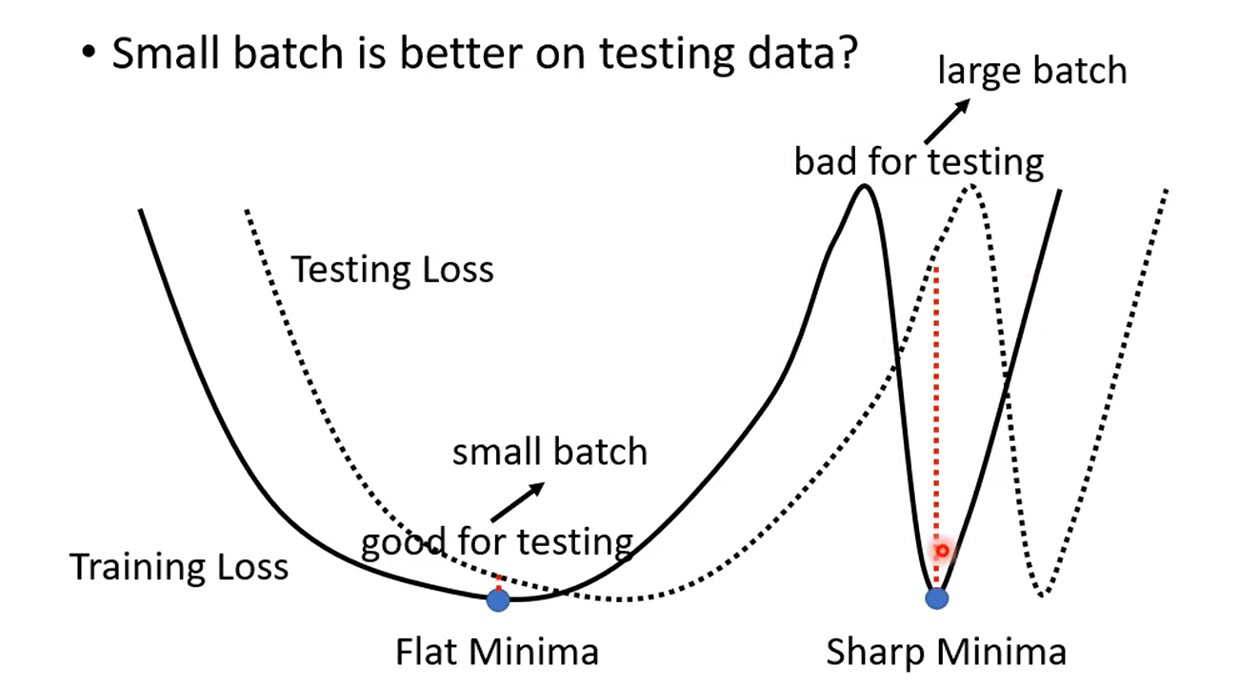
- What wrong with large batch size on testing data? Overfitting
Flat Minima is better than Sharp Minima.
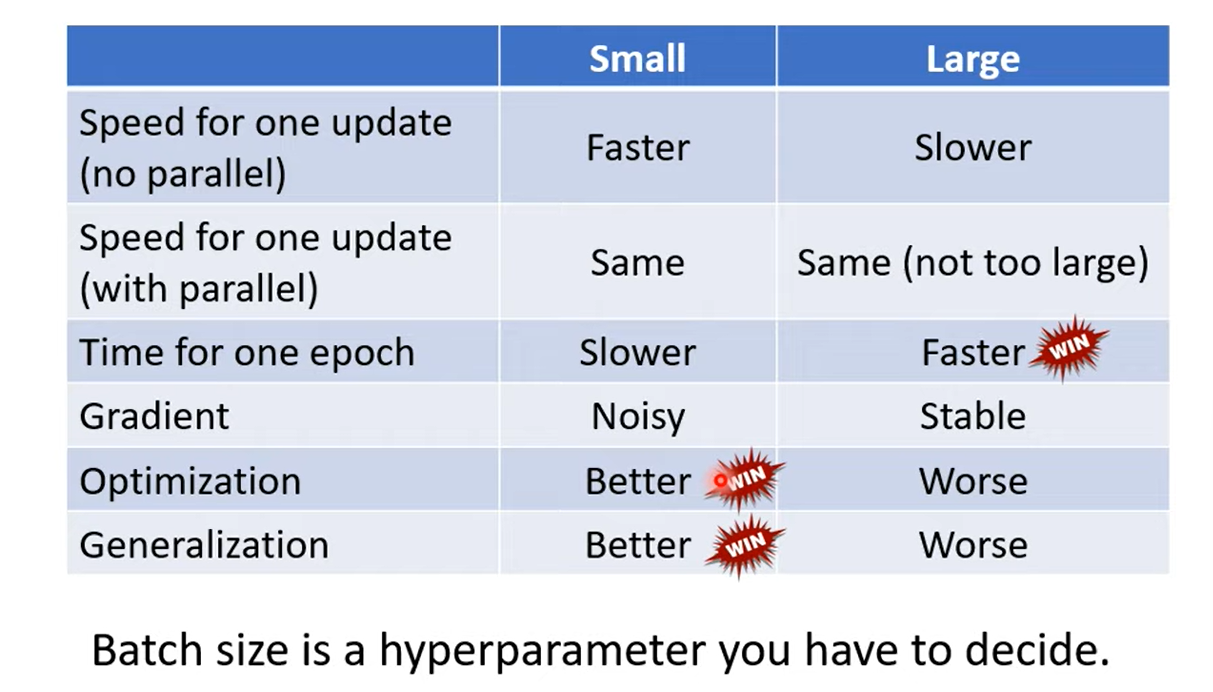
1.3 Comparison
1.3.1 Reference

2 Momentum
2.1 (Vanilla) Gradient Descent
Move in the opposite direction of gradient descent.
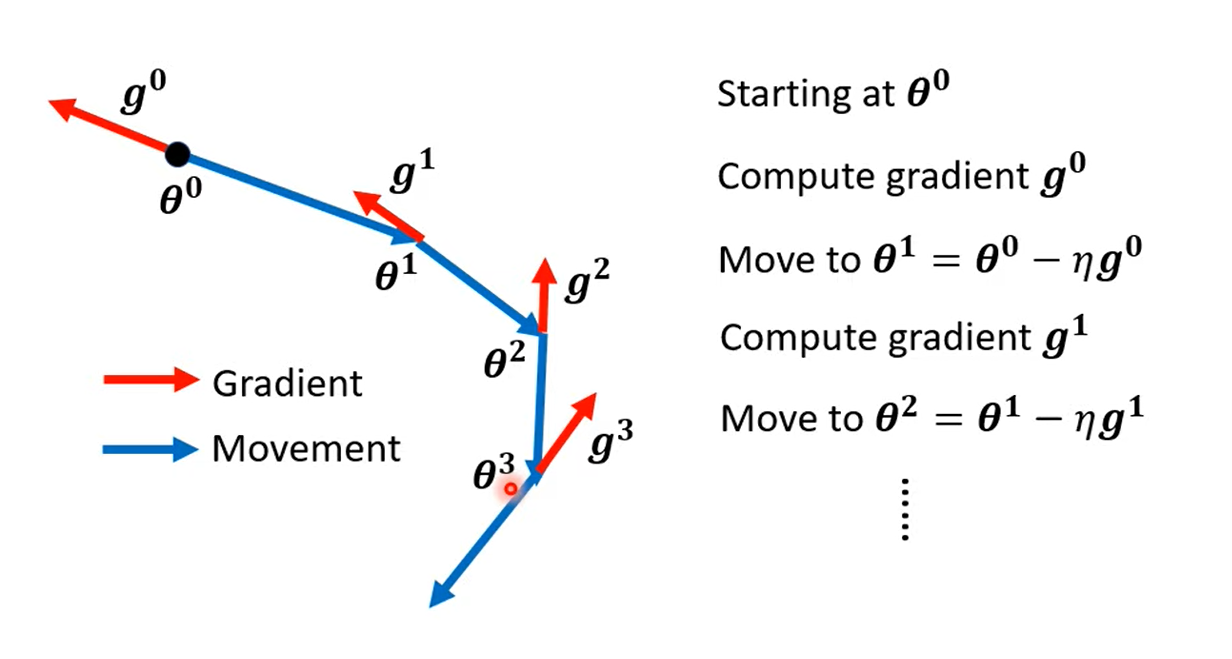
2.2 Gradient Descent + Momentum
Movement: movement of last step minus gradient at present
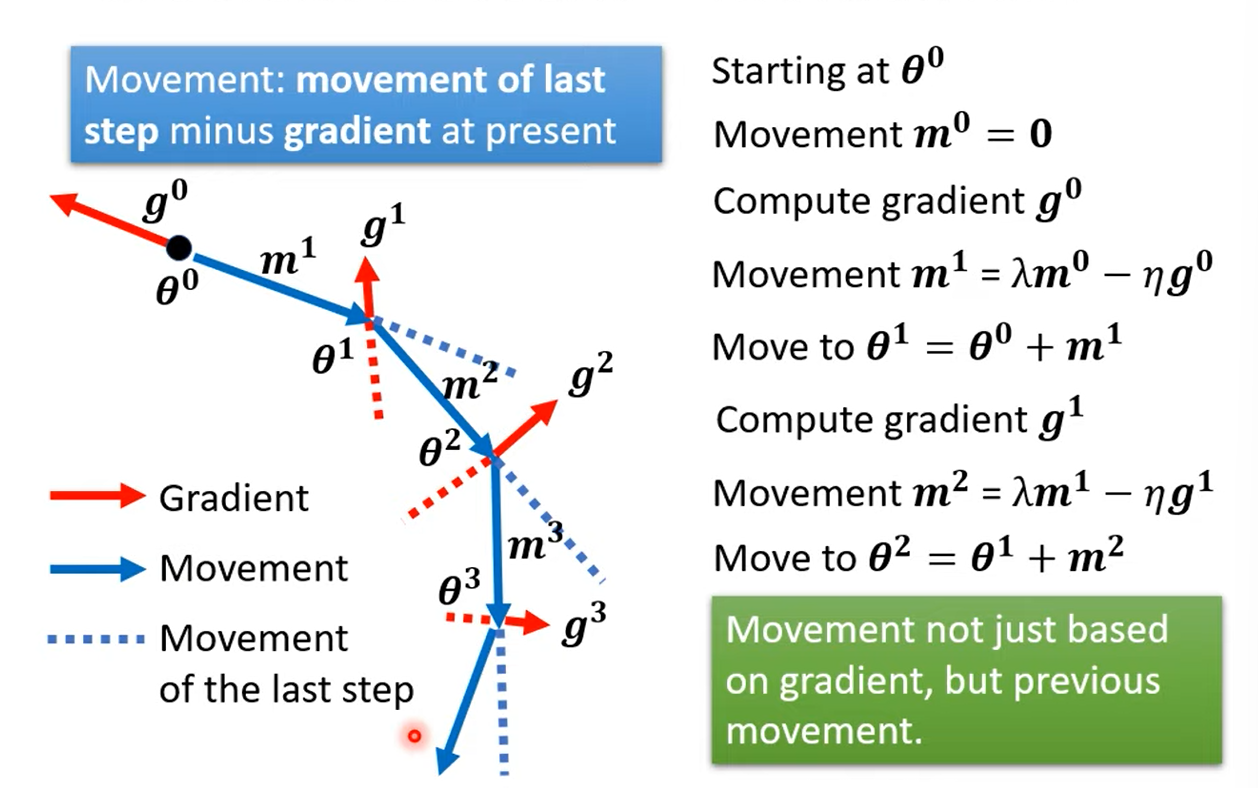
is the weighted sum of all the previous gradient: