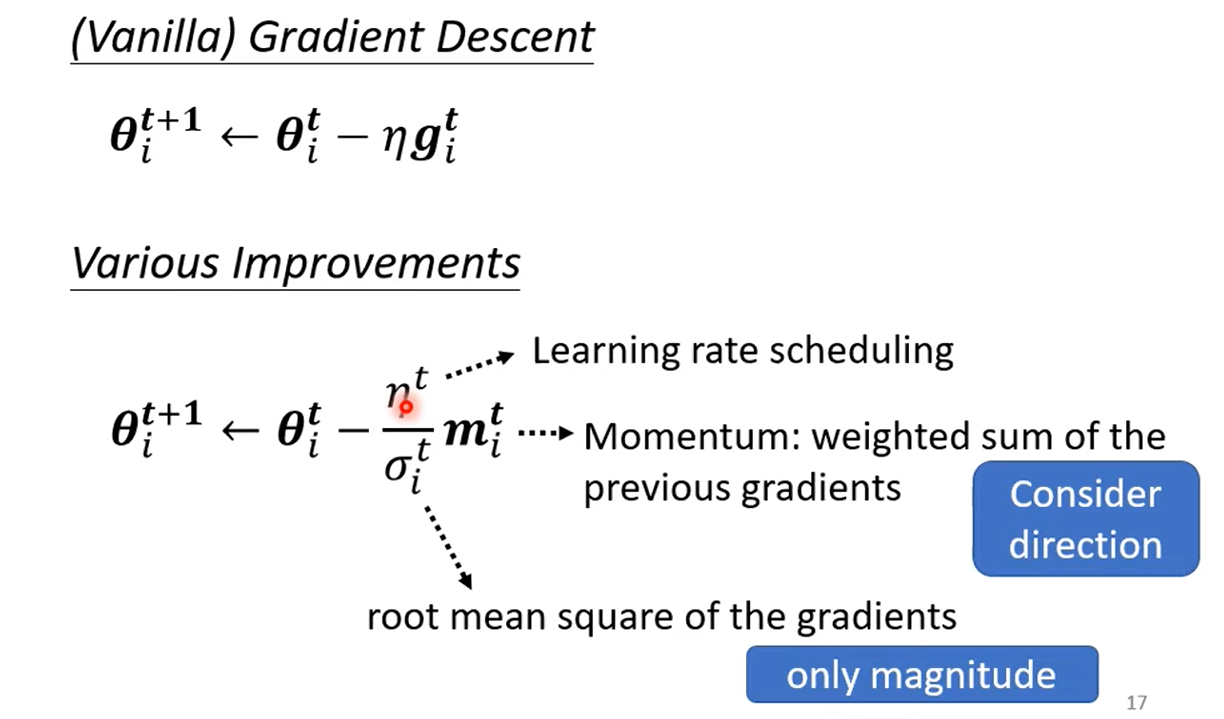
Tips for training: Adapting Learning Rate
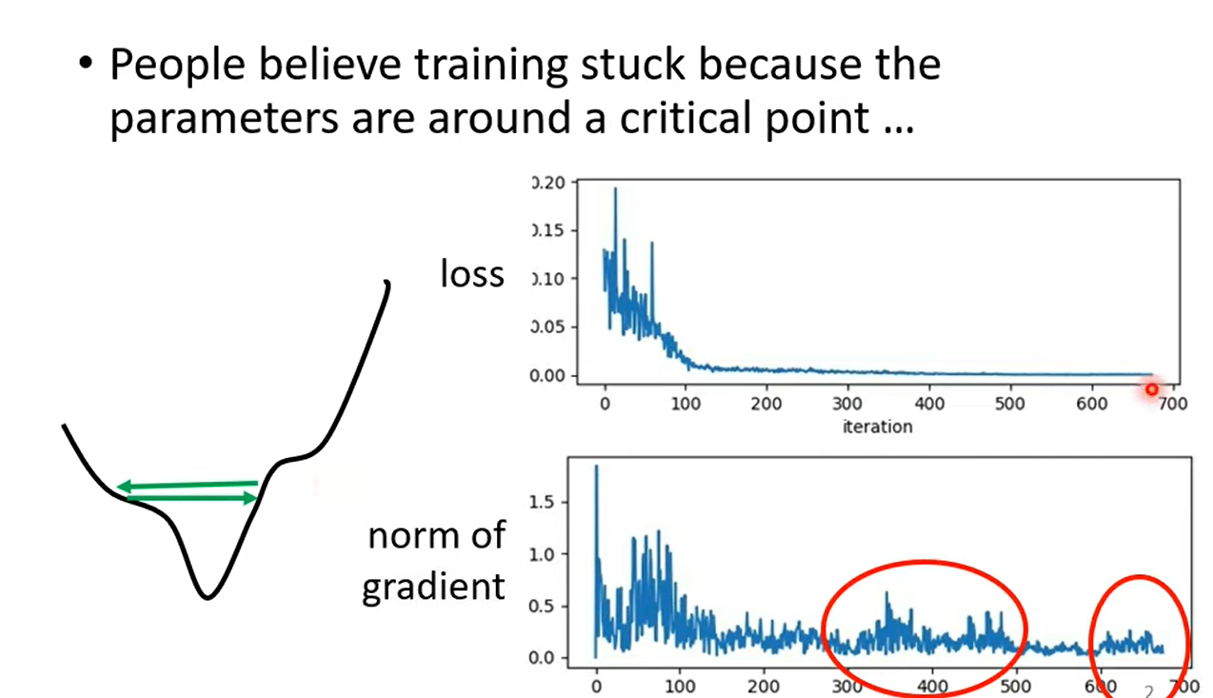
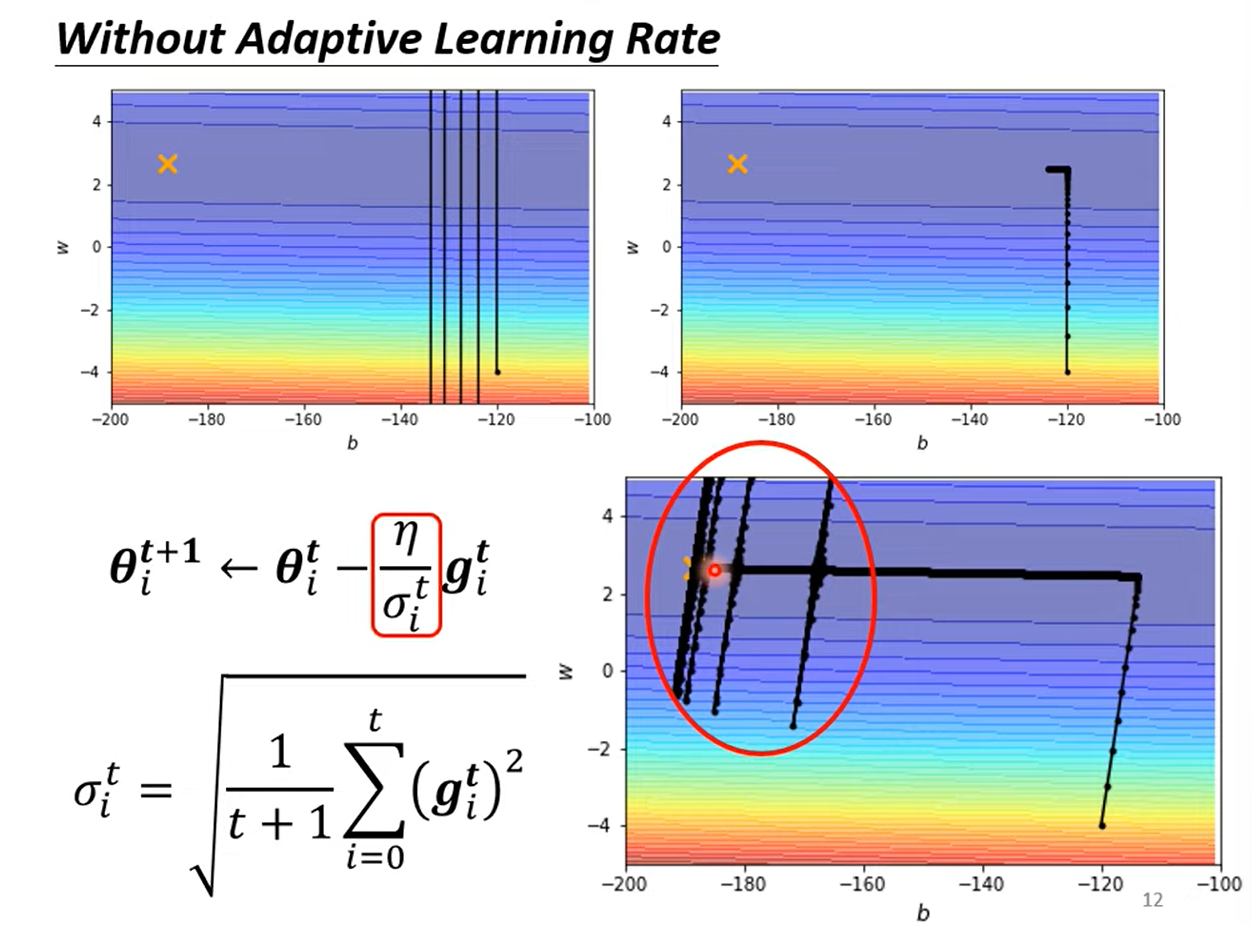
1 Training stuck ≠ Small Gradient
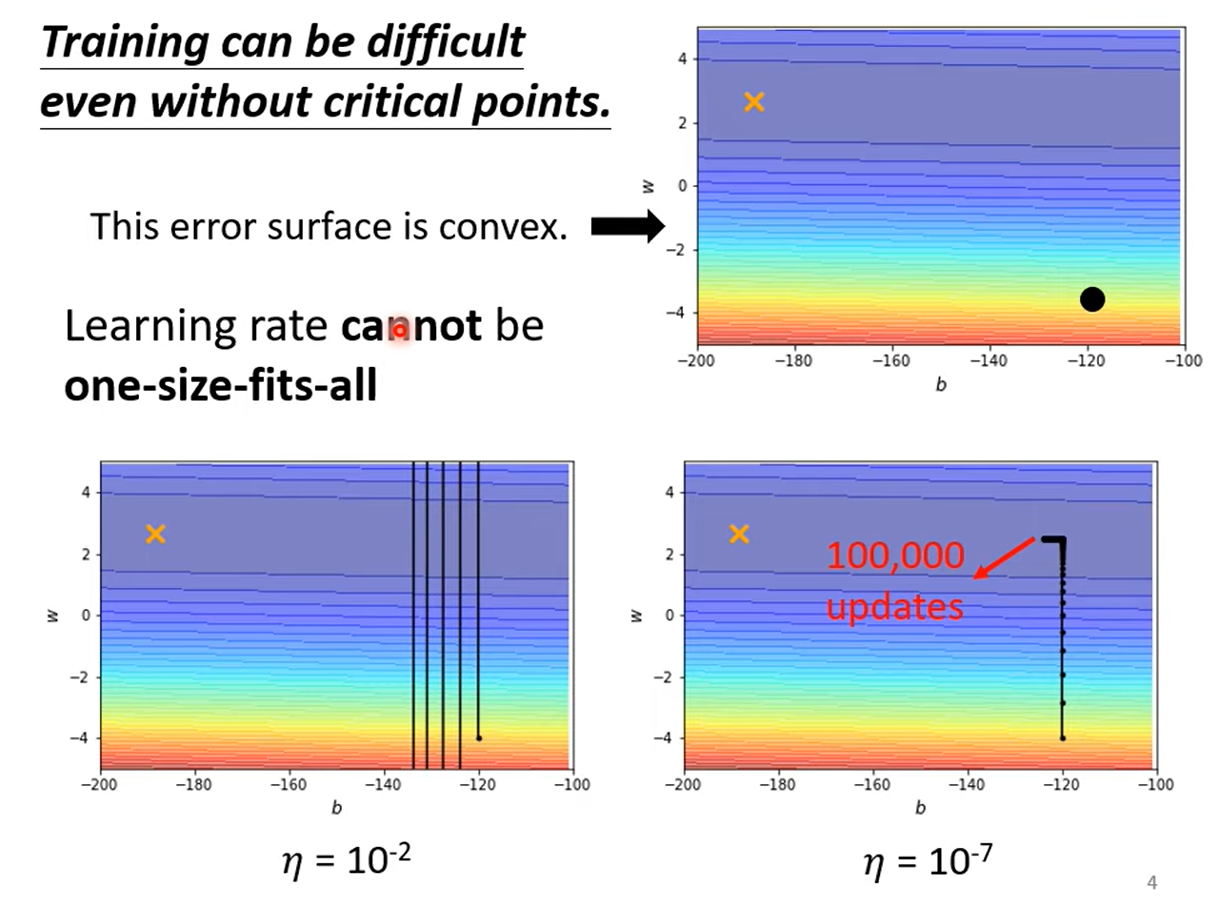
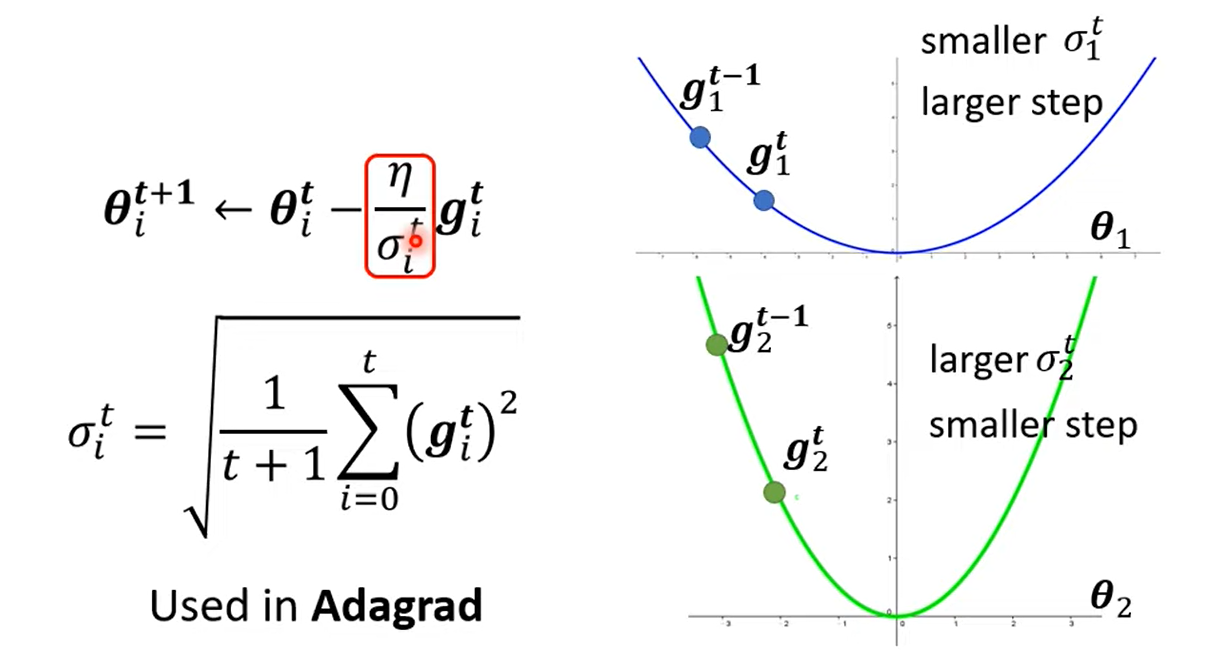
2 Different Parameters Needs Different Learning Rate
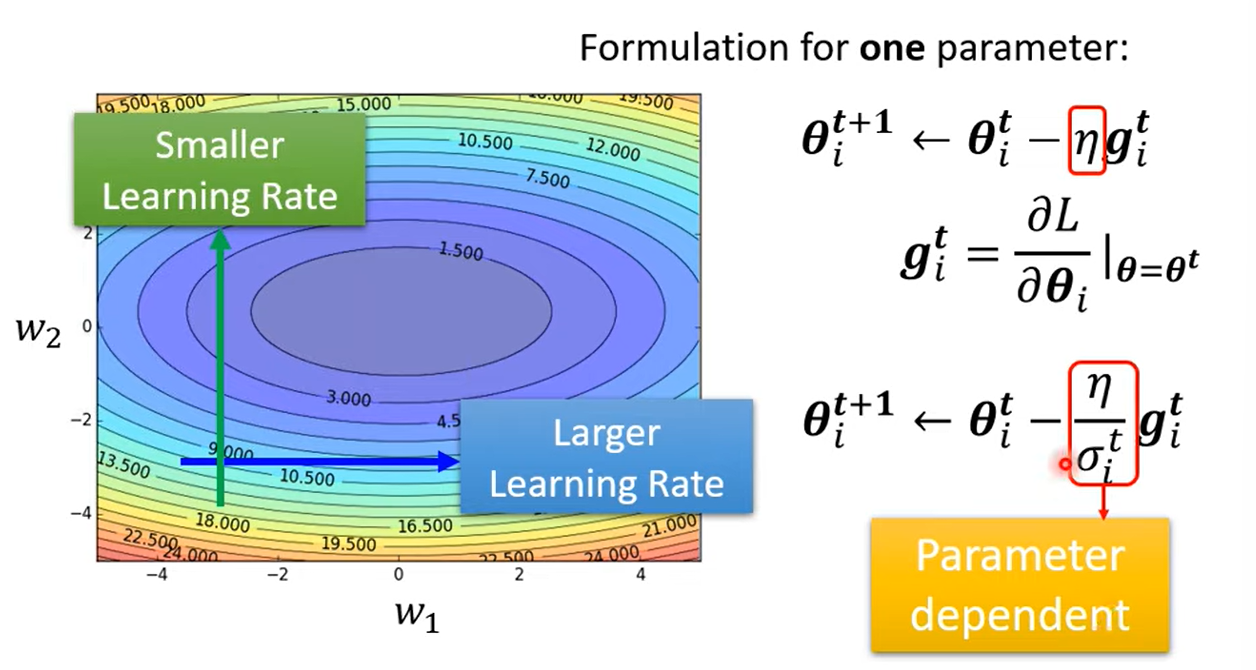
: iteration, : one of the parameter
2.1 Adagrad: Root Mean Square (RMS)
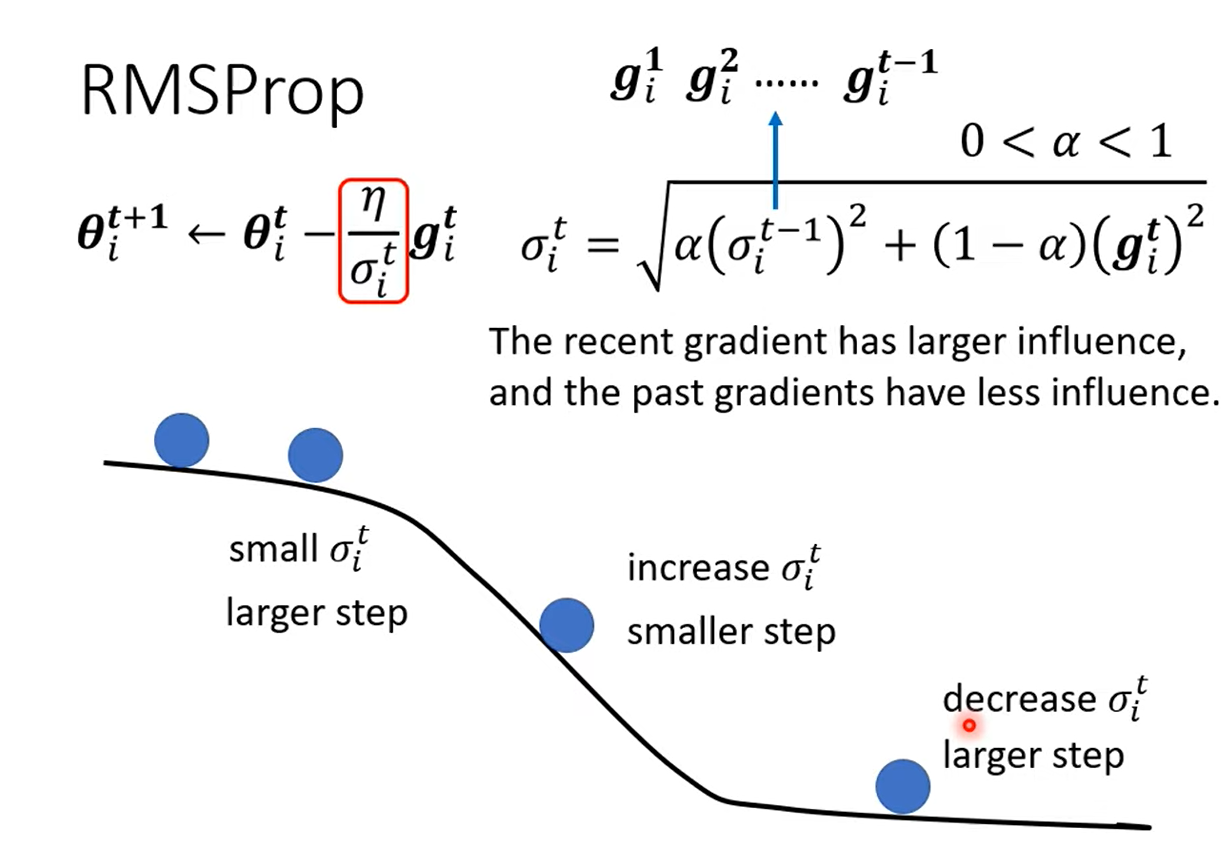
2.2 RMSProp
Learning rate adapts dynamically on the same direction.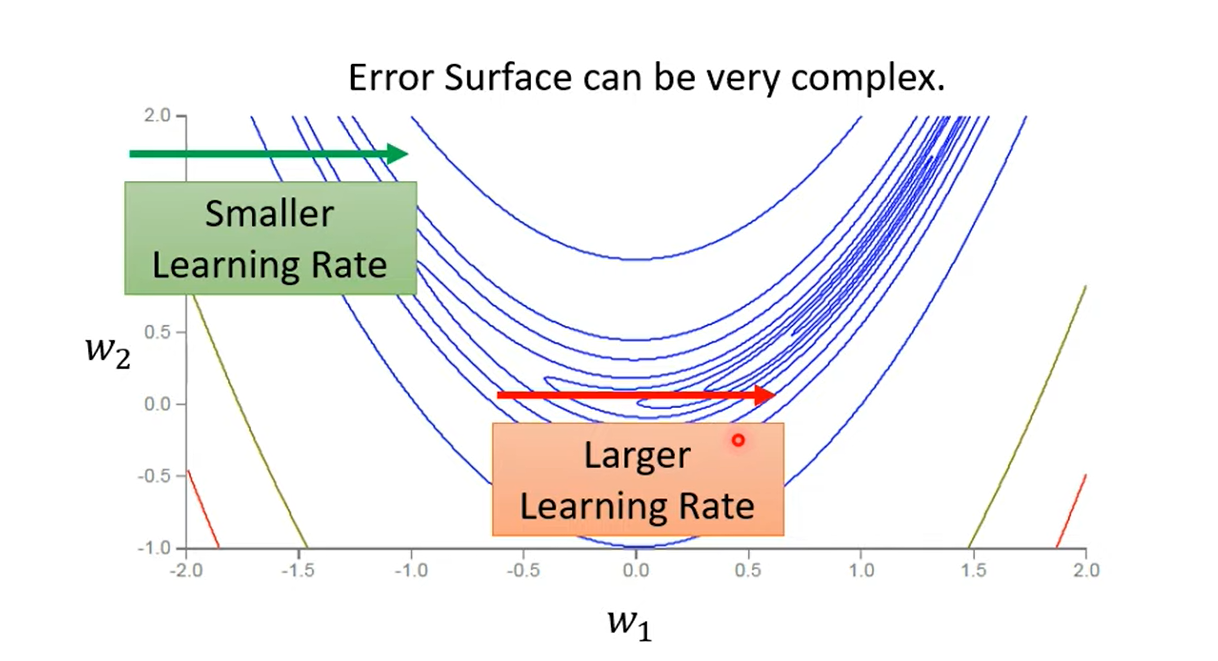
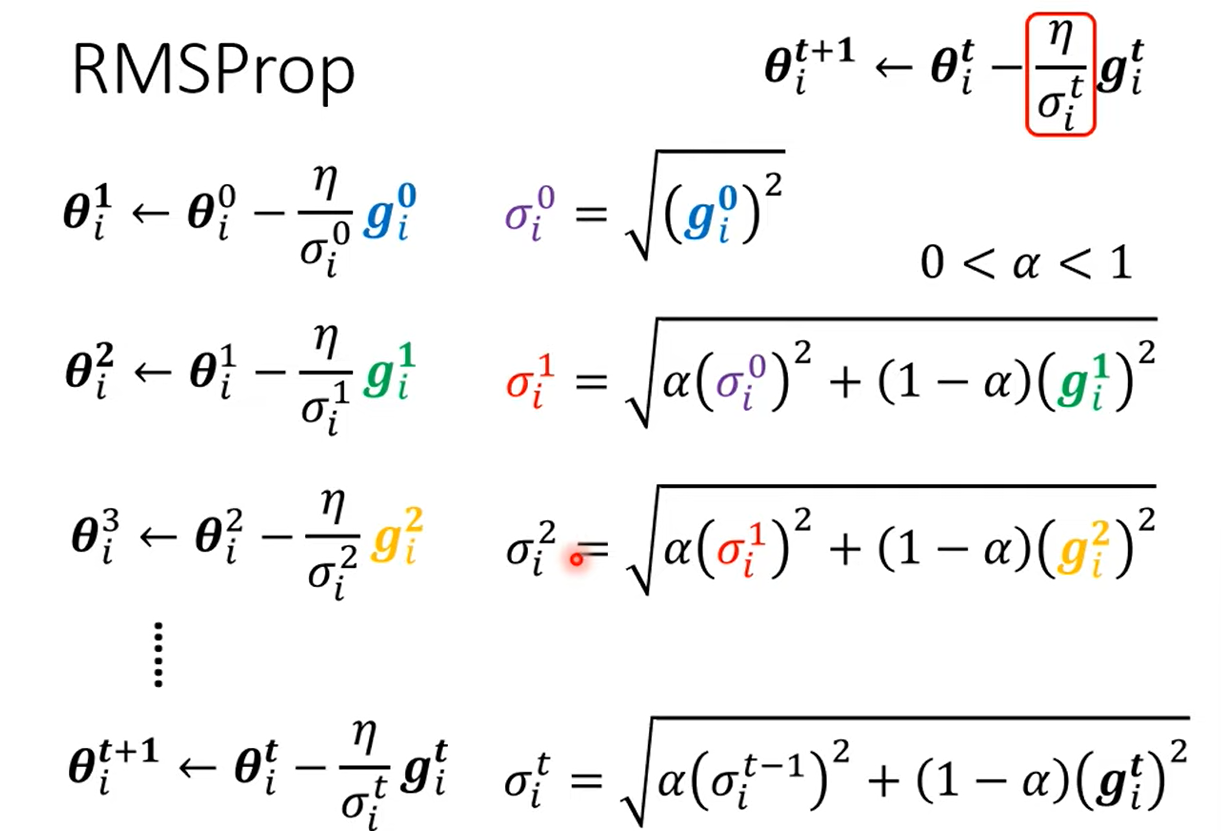
2.3 Adam: RMSProp + Momentum

2.4 Learning Rate Scheduling
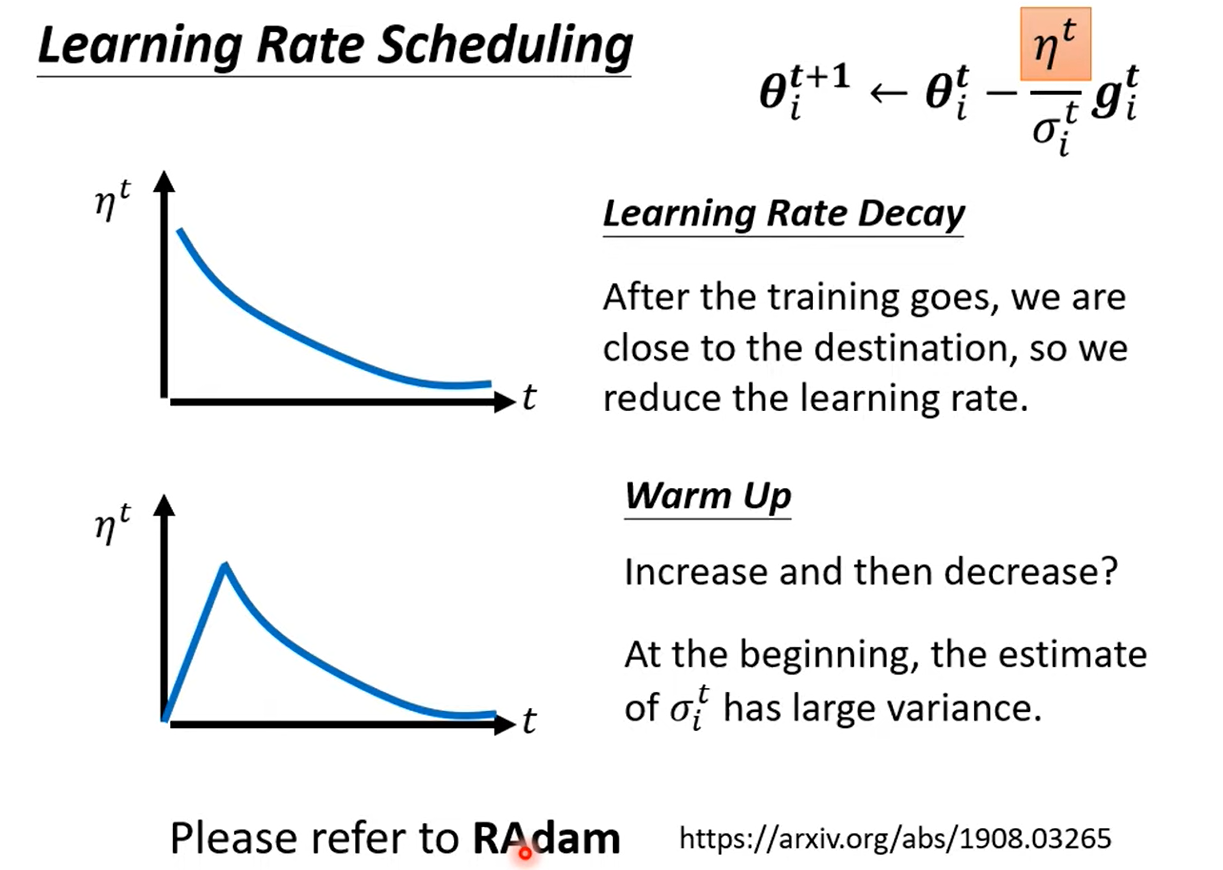
Warm up is used in Residual, Transformer, Bert

2.5 Summary of Optimization