1 The Data Mining Process
Data mining is a general term that encompasses a number of data analysis techniques used to extract meaningful information from (large) data files without necessarily having preconceived notions about what will be discovered. The useful information often consists of patterns and relationships in the data that were previously unknown or even unsuspected.
A common misconception is that data mining involves passing huge amounts of data through intelligent technologies that find patterns and give magical solutions to business problems. This is not true, although data mining does involve more automation than one typically finds in traditional statistical analyses.
Data mining is an interactive and iterative process. Business expertise must be used together with advanced technologies to identify underlying relationships and features in the data. A seemingly useless pattern in data discovered by data mining can often be transformed into a valuable piece of actionable information using business experience and expertise.
Many of the techniques used in data mining are referred to as modeling and require a different approach for model generation and testing compared to standard, traditional statistics. While traditional statistics focuses on probabilities and hypothesis testing using data-specific research, data mining focuses on using historical data accumulated during the normal course of business. It is then the responsibility of the data miner to select, prepare, and analyze the data to determine whether it is acceptable and likely to generalize to the population of interest. Due to the typically large files involved and the weak assumptions made about the distribution of the data, data mining tends to be less focused on statistical significance tests and more focused on practical importance.
Data mining has been used in hundreds of applications, including:
- Detecting fraudulent financial activity;
- Identifying specific purchases that are more likely to lead to additional purchases;
- Classifying customers into groups based on distinct purchase or usage patterns; and
- Predicting which page a website visitor will visit next.
2 The Art and Practice of Data Mining
This is the definition that Keith McCormick has previously used in books and presentations.
Data mining is the selection and analysis of data accumulated during the normal course of business. The goal is to find (and confirm) previously unknown relationships that can be used to develop predictive models that, when applied to new data, can produce valuable insight for making business decisions. Several points are worth emphasizing:
- The data is not new.
- The data is not collected solely to perform data mining.
- The data miner is not testing known relationships (neither hypotheses nor hunches) against the data.
- The patterns must be verifiable.
- The resulting models must be capable of something useful.
- The resulting models must actually work when deployed on new data.
For additional information on data mining, please visit https://keithmccormick.com/data mining-defined/
3 Introducing CRISP-DM
The typical data mining process can become complicated very quickly. There is much to keep track of—complex business problems, multiple data sources, varying data quality across data sources, an array of data mining techniques, different ways of measuring data mining success, and so on. To stay on track, it helps to have an explicitly defined process model for data mining that can guide you through critical issues and ensure that important points are addressed. This process model can serve as a data mining road map that helps you stay on course as you dig into the complexities of the data.
The data mining process model we recommend is the CRoss-Industry Standard Process for Data Mining (CRISP-DM), which is considered the de facto standard for conducting a data mining project. As you can tell from the name, this model is designed as a general model that can be applied to a wide variety of business problems in just about any industry. The model includes six phases starting with business understanding.
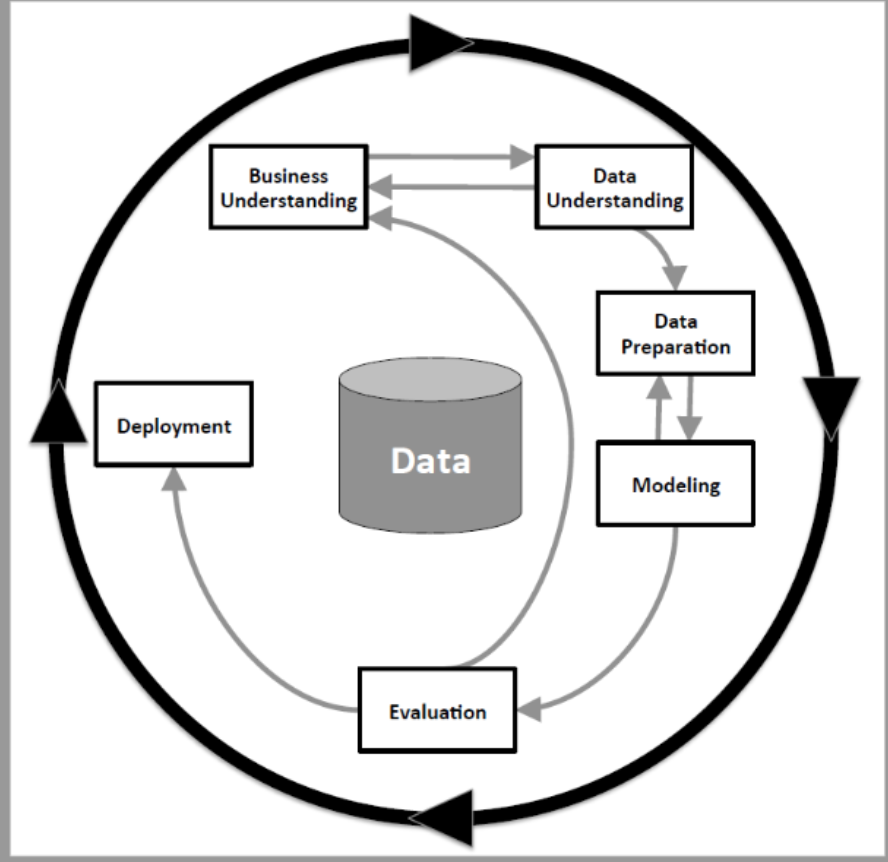
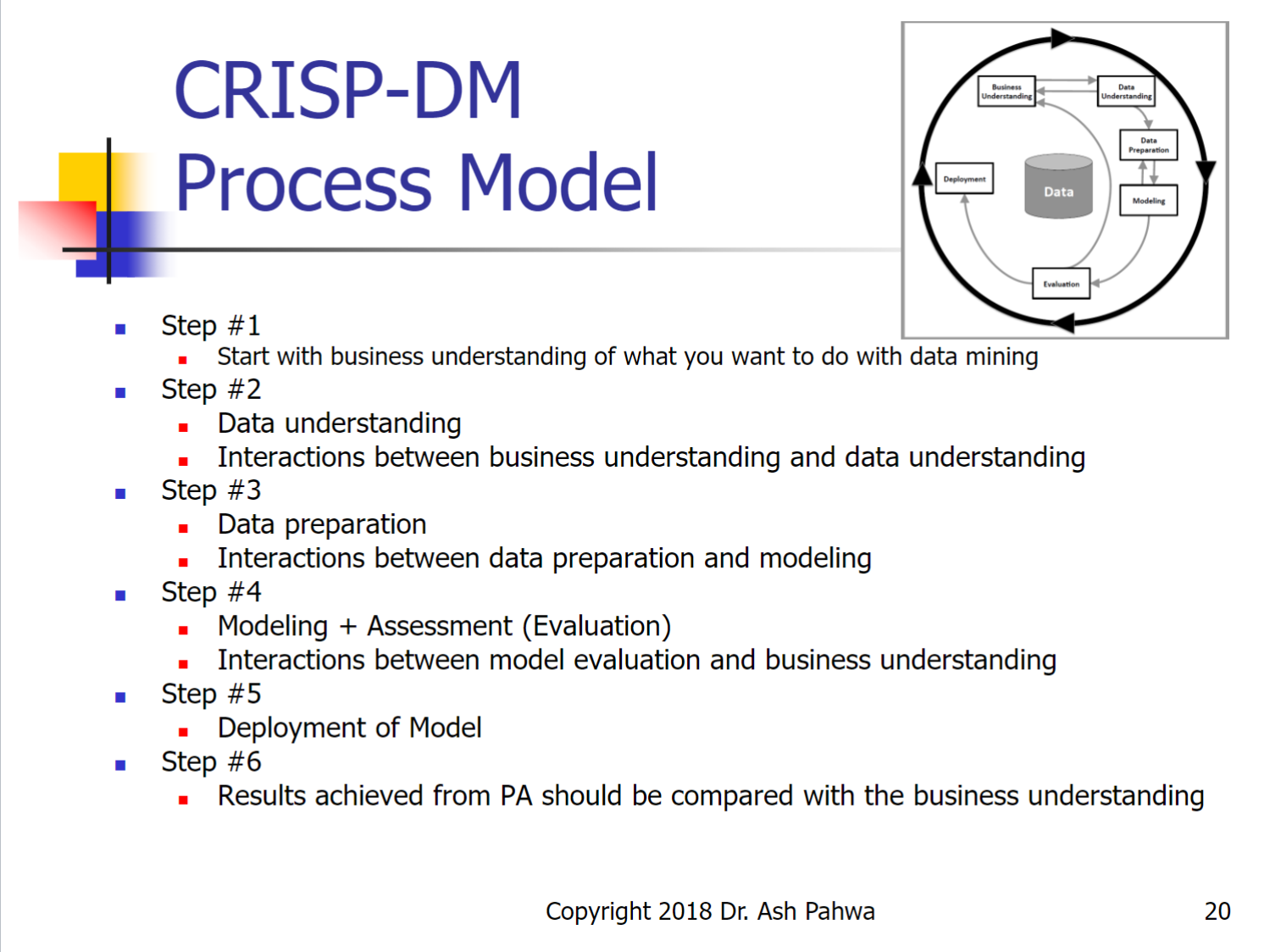
3.1 Business Understanding
The business objectives and question(s) to be answered, and formulating a concrete plan for proceeding through the data mining process. You need to:
- Identify business objectives and success criteria;
- Perform a situational assessment (resources, constraints, assumptions, risks, costs, and benefits);
- Determine the goals of the data mining project;
- Identify success criteria; and
- Produce a project plan.
3.2 Data Understanding
Once the business understanding phase is complete, you’re ready to begin collecting data and associated relevant information (such as the source of the data and the manner in which it was collected) for use in the project. It is also crucial to meet with subject matter experts (SMEs) to review what you have been collecting to ensure completeness (i.e., that no necessary data is missing) and verify your understanding of the data. It is also important to discuss the data in the context of the business problem you’re addressing. Sometimes, it may be necessary to return to the business understanding phase before proceeding.
With data in hand, you can begin exploring it and becoming thoroughly familiar with its characteristics. For each field in your dataset, you should review the distribution, range (for continuous fields), outliers, anomalies, and missing values (type and amount). You can also begin looking for obvious, interesting patterns in the data such as relationships between a predictor and a target field. You’ll need to:
- Understand your data resources;
- Know the characteristics of the data;
- Describe the data;
- Explore the data; and
- Verify data quality.
3.3 Data Preparation
After cataloging your data resources, it’s time to prepare your data for mining. Data preparation is by far the most time-consuming step in the data mining process. Various estimates suggest that 70% to 90% of the time spent on a data mining project is allocated to data preparation; this is because you are using data that was collected for other reasons (for normal business operations, not for data mining). Preparations include:
- Selecting data;
- Cleaning data;
- Constructing data;
- Integrating data; and
- Formatting data.
These tasks will likely be performed multiple times and not in any prescribed order. They can be very time-consuming but are critical for the success of the data mining project. In particular, data construction is a critical aspect of data preparation. Models work much better when the variables have been adjusted (e.g., by creating ratios, determining change scores, and calculating total scores) to make patterns appear more clearly.
3.4 Modeling
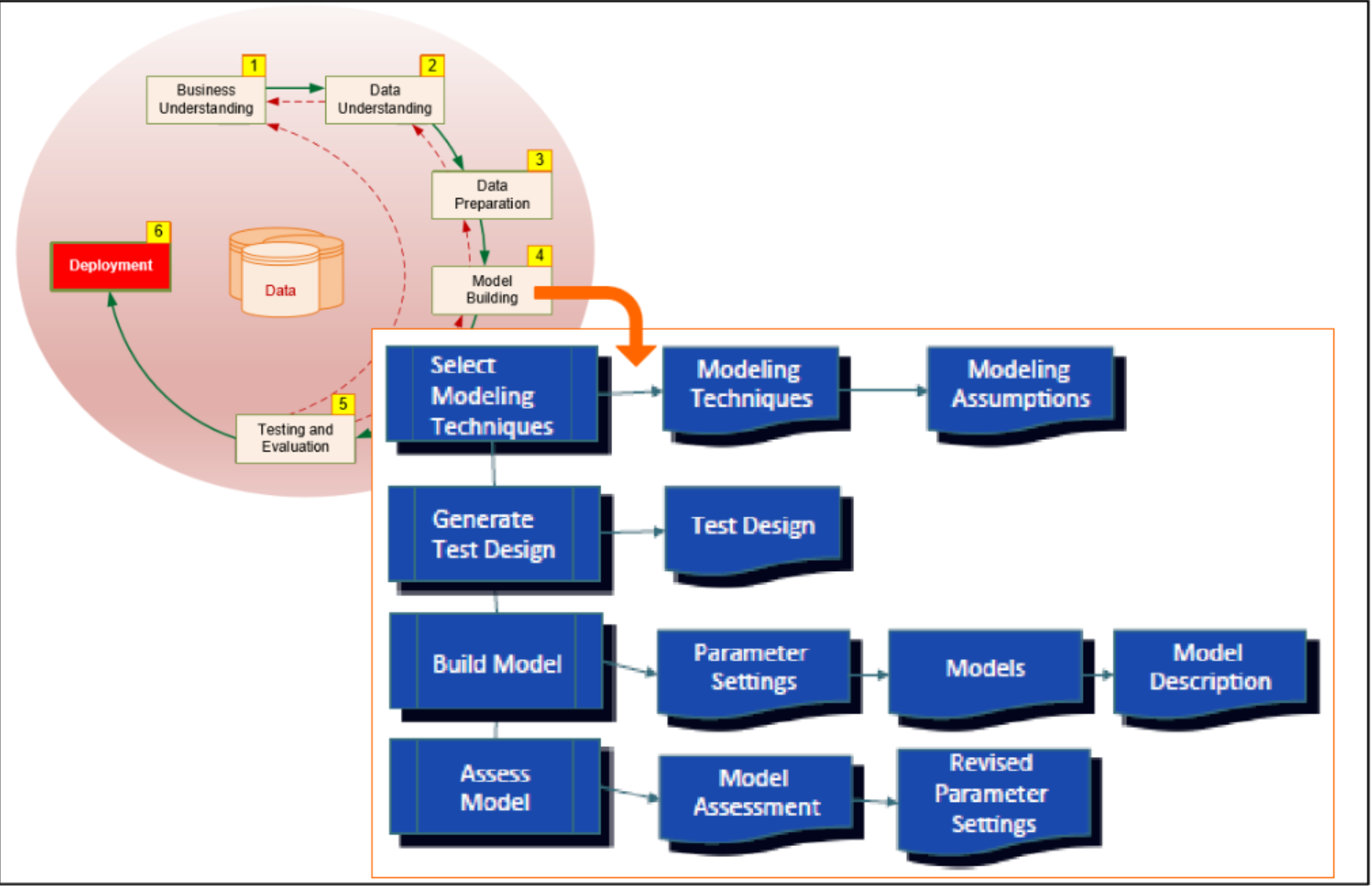
Once you have prepared the data, you are ready for modeling, which involves sophisticated analytical methods that can extract information from the data. This phase involves:
- Selecting the modeling technique;
- Generating a test design;
- Building the model; and
- Assessing the model.
- Validation
- Split the data
- Training: Build the model
- Testing: Test the model with testing dataset and compare the results with observed data
- Split the data
Developing a model is an iterative process and you can expect to try several models and modeling techniques before finding the best one. One feature that separates data mining from other approaches is the use of multiple models to make predictions, building on the strengths of each technique.
An important part of model development is validating the model’s predictive capability. Briefly, the process involves dividing your dataset into two parts: a training dataset and a testing dataset. You develop your model using the training data and then test it by making predictions using the testing data. If the predictions made using the two datasets are in agreement, you can begin applying the model to new data. In summary, you conclude that the model is valid by demonstrating that it applies to (fits) a dataset that is independent of the one used in the model’s derivation. Statisticians often recommend such validation for statistical models, generally, but it is especially important when employing data mining techniques.
3.5 Evaluation
Once you have chosen your models, you are ready to evaluate how the data mining results can help you achieve your business objectives. At this stage of the project, you have built one or more models that appear to be of high quality from a data analysis perspective. Before writing final reports and deploying the model, however, it is important to more thoroughly evaluate the model and review the steps taken in constructing the model so you can be certain it properly achieves your business objectives. A key aim is to determine if there are any important business issues that have not been sufficiently considered. At the end of this phase, a decision will be made on the use of the data mining results. The evaluation phase tasks are:
- Evaluate results;
- Review the process; and
- Determine the next steps.
Evaluation is frequently confused with model assessment—the last task of the modeling phase. Assessing the model focuses on the “data analysis perspective” and includes metrics like model accuracy and stability. The authors of CRISP-DM considered calling this phase business evaluation because it has to be conducted in the language of the business using the metrics of the business as indicators of success. The value of a predictive model arises in two ways (Khabaza, 2010):
- The model’s predictions lead to improved (more effective) action; and
- The model delivers insight (new knowledge), which leads to improved strategy.
Keep in mind that the value of a predictive model is not determined by any technical measure. Data miners should not focus on predictive accuracy, model stability, or any other technical metric for predictive models at the expense of business insight and business fit.
3.6 Deployment
Depending on the business requirements, deployment can be as simple as generating a report or as complex as implementing a repeatable data mining process. Keep in mind that creating the model is generally not the end of the project. Even if the purpose of the model is only to increase one’s knowledge of the data, the knowledge gained will need to be organized and presented in a way that the organization can use for decision-making. So in essentially all projects, a final report will need to be produced and distributed.
Most critical is the deployment of the model to make predictions or create scores against new data. This might be relatively simple if done within the data mining software you used, or more complex if the model is to be applied directly against an existing database. Whatever the case, a plan should be developed to monitor the model’s predictions and success in order to verify that the model is still valid.
In many projects, It is not unusual for the deployment team to be different from the modeling team; in some situations deployment may be the responsibility of team members having more of an IT focus. The tasks in the deployment phase are:
- Plan the deployment;
- Plan monitoring and maintenance activities;
- Produce a final report; and
- Review the project.
See also https://keithmccormick.com/crispdm for additional information about CRISP-DM.
Reference
Course text: UCI. (2020). Introduction to Predictive Analytics.